DeepSieve
综合介绍
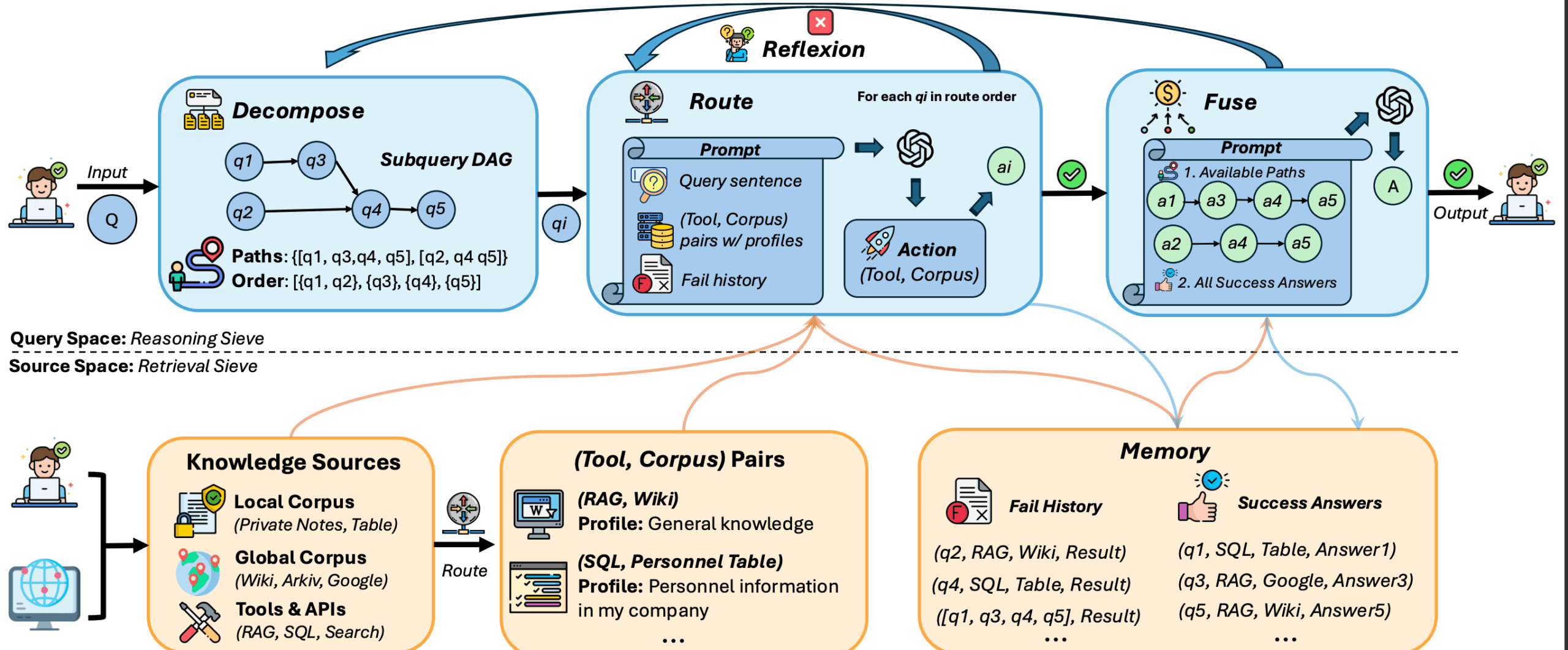
DeepSieve是一个检索增强生成(RAG)框架,其设计旨在解决传统RAG模型难以应对的三大挑战:处理结构完全不同(异构)的知识源(如SQL表、JSON日志和维基百科)、需要多步骤推理的复杂(组合式)问题,以及处理无法合并的隐私感知数据源。为了应对这些挑战,DeepSieve引入了一套新颖的“信息筛选”流水线。该流程首先将一个复杂问题分解为多个具体的子问题;然后,利用大语言模型(LLM)作为一个智能“知识路由器”,为每个子问题匹配最合适的工具和知识库组合进行查询;如果某次检索失败,系统会启动反思机制并进行重试;最后,它将所有检索到的零散答案融合,生成一个全面的最终回复。这个框架的所有核心组件都是模块化的,允许用户根据具体需求开启或关闭,提供了高度的灵活性。
相关链接
- 论文预印本:
https://arxiv.org/abs/2507.22050 - 项目网站:
https://minghokwok.github.io/deepsieve
功能列表
- 查询分解: 能够将一个复杂的、需要多步推理的组合式查询,自动分解成一系列具体的、可执行的子问题。
- 知识路由: 使用大语言模型作为路由器,为每个子问题智能地匹配并引导到最合适的“工具-知识库”组合,从而有效查询SQL、JSON、文本等不同结构的数据。
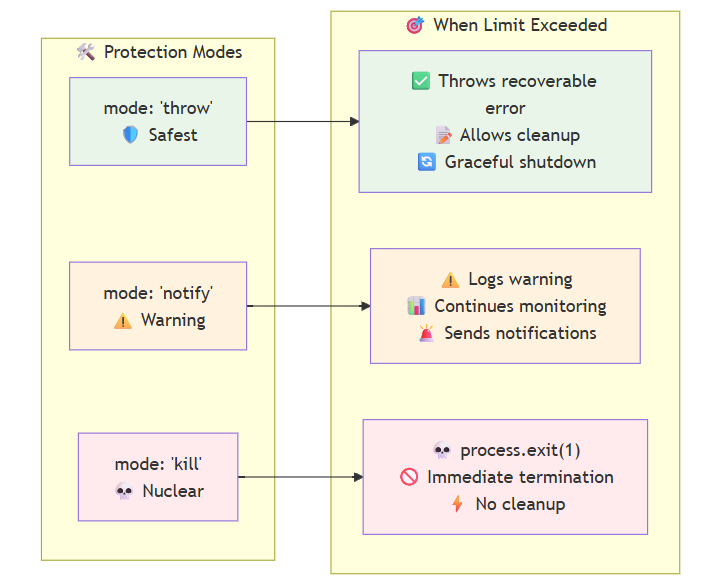
- 反思与重试: 当对某个子问题的检索失败或返回信息不充分时,系统会自动启动反思机制,尝试重新规划查询并进行重试(可设置最大重试次数)。
- 答案融合: 将所有子问题检索到的局部答案进行整合,最终生成一个逻辑连贯、内容完整的最终回复。
- 处理异构知识源: 核心优势之一,能够同时处理和查询多种结构完全不同的数据源,例如结构化的SQL表、半结构化的JSON日志和非结构的维基百科文章。
- 支持隐私感知场景: 框架的设计允许在数据源相互隔离、无法合并的情况下进行查询,适用于注重数据隐私的场景。
- 模块化设计: 框架的核心组件(查询分解、路由、反思)都可以通过命令行参数独立开启或关闭,提供了高度的灵活性和可定制性。
- 双RAG后端: 支持
naive(朴素)和graph(图)两种不同的RAG实现模式,用户可以根据需求在环境变量中轻松切换。 - 详细日志与追踪: 每次运行都会生成详细的日志文件,记录了每个查询的处理结果、融合过程的提示以及最终的性能指标,便于分析和调试。
使用帮助
DeepSieve是一个用于提升大语言模型(LLM)问答能力的高级框架。它通过一系列精巧的步骤,从未经整理的、多样化的数据源中筛选并提取准确信息来回答复杂问题。下面将详细介绍如何配置并使用此框架。
环境配置
在开始使用DeepSieve之前,你需要先配置好本地的运行环境。
- 安装依赖组件首先,需要安装所有必要的Python库。DeepSieve项目根目录中提供了一个
requirements.txt文件,包含了所有依赖项。打开你的终端或命令行工具,进入项目文件夹,然后运行以下命令:pip install -r requirements.txt这个命令会自动下载并安装框架运行所需的全部第三方库。
- 设置环境变量DeepSieve需要连接一个大语言模型(LLM)服务来执行分解、路由和融合等核心任务。你需要将你的LLM API凭证设置为环境变量,以便程序能够访问。
在终端中执行以下命令,将
your_api_key替换成你自己的API密钥:export OPENAI_API_KEY=your_api_key接着,你需要指定使用的具体模型。例如,如果使用
deepseek-chat模型,则运行:export OPENAI_MODEL=deepseek-chat如果你的LLM服务商使用了非官方的API地址(API Base),你也需要配置它。例如:
export OPENAI_API_BASE=https://api.deepseek.com/v1最后,你需要指定要使用的RAG后端类型。DeepSieve支持
naive和graph两种模式。对于初次使用者,建议从naive模式开始。export RAG_TYPE=naive完成以上配置后,你的环境就准备就绪了。
基本使用方法
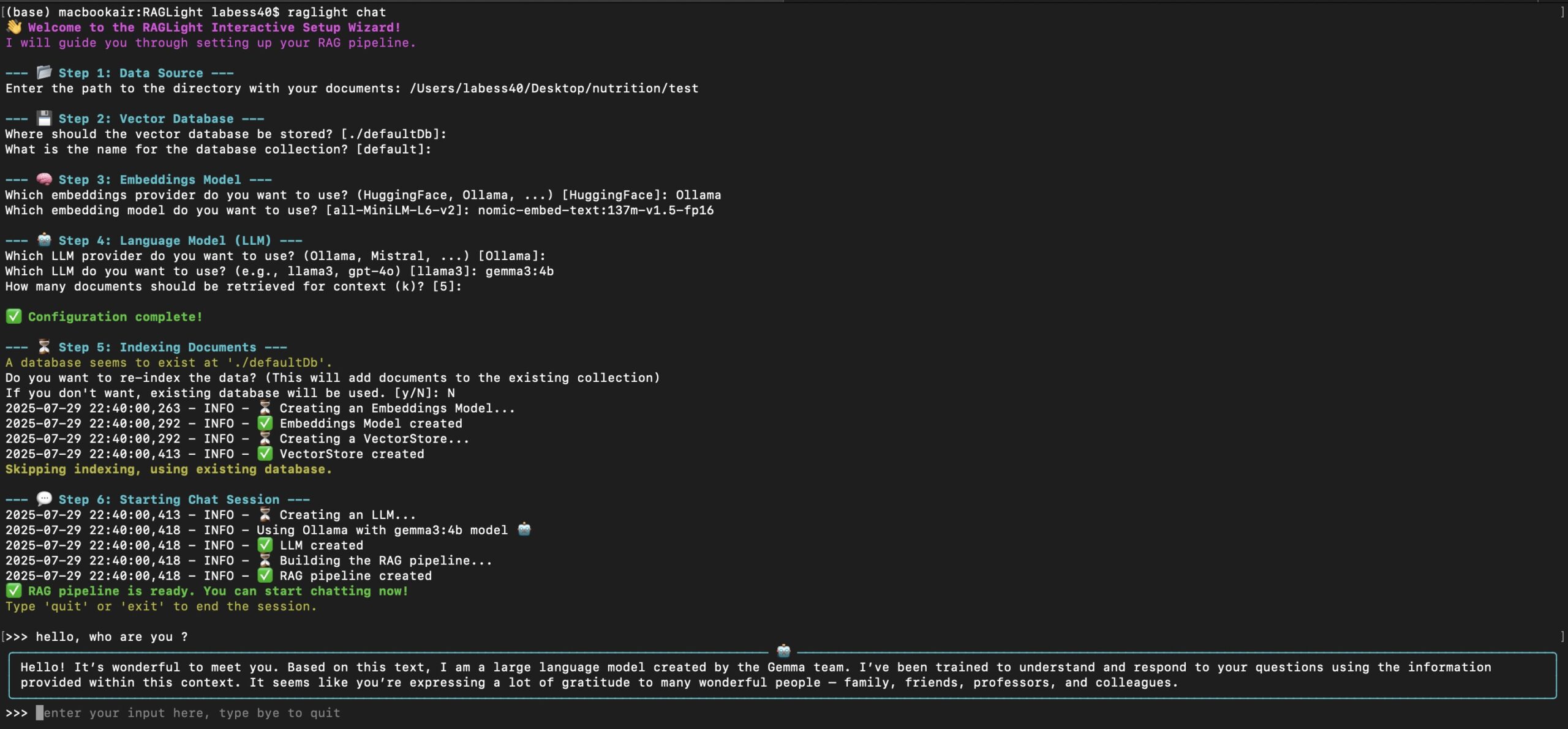
配置好环境后,你可以通过运行主程序main_rag_only.py来启动完整的RAG流水线。
一个典型的运行命令如下:
python runner/main_rag_only.py \
--dataset hotpot_qa \
--sample_size 100 \
--decompose \
--use_routing \
--use_reflection \
--max_reflexion_times 2
这个命令启动了一个完整的处理流程,我们来分解一下各个参数的作用:
--dataset hotpot_qa: 指定了使用hotpot_qa这个数据集作为问题来源。--sample_size 100: 表示将从数据集中随机抽取100个样本进行处理。--decompose: 激活“查询分解”功能。程序会先将复杂问题拆解成子问题。--use_routing: 激活“知识路由”功能。程序会为每个子问题智能选择数据源。--use_reflection: 激活“反思”功能。当检索结果不佳时,程序会进行重试。--max_reflexion_times 2: 设置“反思”功能的最大重试次数为2次。
模块化功能开关
DeepSieve的强大之处在于其模块化的设计。你可以通过在运行命令中添加或移除参数来开启或关闭特定功能,这对于调试和理解每个模块的作用非常有帮助。
- 禁用查询分解: 如果你希望模型直接处理原始问题,而不是先进行分解,只需在命令中移除
--decompose参数即可。 - 禁用知识路由: 如果移除
--use_routing参数,系统将不会智能选择知识源,而是使用默认的检索方式。 - 禁用反思机制: 如果移除
--use_reflection参数,系统在遇到检索失败时将不会进行重试。
例如,一个最简化的运行命令可能如下所示,它只执行基本的RAG检索,而不进行分解、路由或反思:
python runner/main_rag_only.py \
--dataset hotpot_qa \
--sample_size 100
切换RAG后端模式
你可以通过修改环境变量RAG_TYPE来切换不同的RAG后端。
- 使用Naive RAG模式(默认):
export RAG_TYPE=naive python runner/main_rag_only.py --dataset hotpot_qa ... - 切换到Graph RAG模式:
export RAG_TYPE=graph python runner/main_rag_only.py --dataset hotpot_qa ...
输出结果解读
每次运行结束后,程序会在outputs/目录下生成详细的输出文件。
- 单个查询结果: 在
outputs/{rag_type}_{dataset}*/路径下,会有一个名为query_{i}_results.jsonl的文件。这个文件以JSONL格式记录了第i个查询的完整处理过程和最终结果。 - 融合过程提示:
outputs/.../query_{i}_fusion_prompt.txt文件记录了在最后一步“答案融合”时,系统提供给大语言模型的完整提示(Prompt),这对于理解模型如何整合信息非常有价值。 - 总体性能报告:
overall_results.txt和overall_results.json这两个文件汇总了本次运行所有样本的性能指标,例如准确率、召回率等,帮助你从宏观上评估框架的表现。
应用场景
- 企业级知识库问答大型企业内部通常拥有多种格式的知识库,如存放在数据库中的产品参数、PDF格式的说明文档和网页形式的FAQ。当员工或客户提出一个横跨多个知识源的复杂问题时,例如“对比A型号和B型号产品的最新功能差异,并说明它们分别适合哪些应用场景”,DeepSieve能够将问题分解,分别查询数据库和文档,然后融合答案,提供精准回复。
- 支持隐私保护的医疗查询在医疗领域,患者的电子病历(EHR)是高度私密的,不能与公开的医学文献数据库(如PubMed)直接合并。医生可以提出问题:“结合患者张三的过敏史和当前的症状,查询最新的公开文献,有哪些潜在的治疗方案?”DeepSieve可以分别查询私有的EHR数据库和公共的PubMed,在不泄露隐私数据的前提下,整合信息并提供建议。
- 金融与市场分析金融分析师需要结合结构化的市场数据(如股价、财报)和非结构化的新闻、研报来做出决策。他们可以向DeepSieve提出问题,如“分析X公司上季度的财报表现,并结合近期的市场新闻,评估其下一季度的增长潜力”。DeepSieve能够分别从SQL数据库和新闻网站中提取信息,并生成一份综合性的分析报告。
- 智能客服系统高级智能客服需要处理用户模糊且多样的查询。一个用户可能会问:“我的订单为什么延迟了,另外,你们最新的退货政策是什么?”。DeepSieve可以将此分解为两个子问题,一个查询订单数据库,另一个查询知识库中的退货政策文档,从而提供全面、准确的答复,提升用户满意度。
QA
- DeepSieve和传统的RAG框架有什么核心区别?核心区别在于DeepSieve专门为解决三个传统RAG的痛点而设计:一是处理异构知识源,能同时查询SQL、JSON、文本等不同结构的数据;二是处理组合式查询,能通过分解和多步推理回答复杂问题;三是支持隐私感知,能在数据源无法合并的情况下独立查询并融合结果。传统RAG通常在处理这类复杂、异构、需要保护隐私的场景时效果不佳。
- 这个框架是否需要付费的大语言模型API才能运行?是的。DeepSieve的核心功能,如查询分解、知识路由和答案融合,都依赖于一个强大的大语言模型(LLM)来执行。因此,你需要一个LLM的API密钥(例如来自OpenAI, DeepSeek等服务商),并将其配置在环境变量中。框架本身是开源免费的,但调用LLM API会产生相应费用。
- 如果我对某个子问题的检索结果不满意,可以手动干预吗?在当前的自动化框架设计中,手动干预不是其标准工作流程的一部分。但是,框架的“反思”(Reflection)机制在一定程度上实现了自动纠错。当它检测到检索结果不充分或失败时,会尝试重新规划路由或分解。此外,由于代码是开源的,高级用户可以修改代码,在特定节点加入人工校验或干预的逻辑。
- 什么是Naive RAG和Graph RAG模式,我应该如何选择?
naive(朴素)模式和graph(图)模式是框架提供的两种不同的RAG后端实现。naive模式可能代表了一种更直接、线性的检索流程,适合作为基线或在数据结构相对简单的场景下使用。graph模式则可能利用知识图谱等技术来组织和检索信息,更适合处理实体和关系复杂的查询。对于大多数初学者,建议从naive模式开始,如果发现其无法满足复杂的推理需求,再尝试切换到graph模式进行实验。